HADOOP-PR000007 Online Practice Questions and Answers
You want to count the number of occurrences for each unique word in the supplied input data. You've decided to implement this by having your mapper tokenize each word and emit a literal value 1, and then have your reducer increment a counter for each literal 1 it receives. After successful implementing this, it occurs to you that you could optimize this by specifying a combiner. Will you be able to reuse your existing Reduces as your combiner in this case and why or why not?
A. Yes, because the sum operation is both associative and commutative and the input and output types to the reduce method match.
B. No, because the sum operation in the reducer is incompatible with the operation of a Combiner.
C. No, because the Reducer and Combiner are separate interfaces.
D. No, because the Combiner is incompatible with a mapper which doesn't use the same data type for both the key and value.
E. Yes, because Java is a polymorphic object-oriented language and thus reducer code can be reused as a combiner.
Examine the following Hive statements:
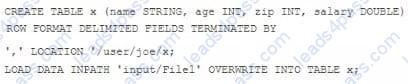
Assuming the statements above execute successfully, which one of the following statements is true?
A. Hive reformats File1 into a structure that Hive can access and moves into to/user/joe/x/
B. The file named File1 is moved to to/user/joe/x/
C. The contents of File1 are parsed as comma-delimited rows and loaded into /user/joe/x/
D. The contents of File1 are parsed as comma-delimited rows and stored in a database
You need to move a file titled "weblogs" into HDFS. When you try to copy the file, you can't. You know you have ample space on your DataNodes. Which action should you take to relieve this situation and store more files in HDFS?
A. Increase the block size on all current files in HDFS.
B. Increase the block size on your remaining files.
C. Decrease the block size on your remaining files.
D. Increase the amount of memory for the NameNode.
E. Increase the number of disks (or size) for the NameNode.
F. Decrease the block size on all current files in HDFS.
MapReduce v2 (MRv2/YARN) is designed to address which two issues?
A. Single point of failure in the NameNode.
B. Resource pressure on the JobTracker.
C. HDFS latency.
D. Ability to run frameworks other than MapReduce, such as MPI.
E. Reduce complexity of the MapReduce APIs.
F. Standardize on a single MapReduce API.
What data does a Reducer reduce method process?
A. All the data in a single input file.
B. All data produced by a single mapper.
C. All data for a given key, regardless of which mapper(s) produced it.
D. All data for a given value, regardless of which mapper(s) produced it.
You have the following key-value pairs as output from your Map task:
(the, 1)
(fox, 1)
(faster, 1)
(than, 1)
(the, 1) (dog, 1)
How many keys will be passed to the Reducer's reduce method?
A. Six
B. Five
C. Four
D. Two
E. One
F. Three
You are developing a combiner that takes as input Text keys, IntWritable values, and emits Text keys, IntWritable values. Which interface should your class implement?
A. Combiner
B. Mapper
C. Reducer
D. Reducer
E. Combiner
MapReduce v2 (MRv2/YARN) splits which major functions of the JobTracker into separate daemons? Select two.
A. Heath states checks (heartbeats)
B. Resource management
C. Job scheduling/monitoring
D. Job coordination between the ResourceManager and NodeManager
E. Launching tasks
F. Managing file system metadata
G. MapReduce metric reporting H. Managing tasks
You write MapReduce job to process 100 files in HDFS. Your MapReduce algorithm uses TextInputFormat: the mapper applies a regular expression over input values and emits key- values pairs with the key consisting of the matching text, and the value containing the filename and byte offset. Determine the difference between setting the number of reduces to one and settings the number of reducers to zero.
A. There is no difference in output between the two settings.
B. With zero reducers, no reducer runs and the job throws an exception. With one reducer, instances of matching patterns are stored in a single file on HDFS.
C. With zero reducers, all instances of matching patterns are gathered together in one file on HDFS. With one reducer, instances of matching patterns are stored in multiple files on HDFS.
D. With zero reducers, instances of matching patterns are stored in multiple files on HDFS. With one reducer, all instances of matching patterns are gathered together in one file on HDFS.
Given the following Hive command:
INSERT OVERWRITE TABLE mytable SELECT * FROM myothertable;
Which one of the following statements is true?
A. The contents of myothertable are appended to mytable
B. Any existing data in mytable will be overwritten
C. A new table named mytable is created, and the contents of myothertable are copied into mytable
D. The statement is not a valid Hive command
![]()
![]()
![]()
![]()
![]()
![]()
All rights are reserved by
leads4pass.com. Any changes, copy or trademarks abuse will be
regarded as infringement.
leads4pass.com will reserve the right to pursue accountability.
Copyright © 2004-
2026 leads4pass.com.