E20-065 Online Practice Questions and Answers
A data engineer is asked to process several large datasets using MapReduce. Upon initial inspection the engineer realizes that there are complex interdependencies between the datasets.
Why is this a problem?
A. MapReduce works best on unstructured data
B. There is no problem; MapReduce accommodates all the data
C. MapReduce can only parse one file at a time.
D. MapReduce is not ideal when the processing of one dataset depends on another.
What is the most likely reason for an HBase table to contain millions of columns?
A. Data is imported from a relational database table
B. Data is stored in the column qualifier
C. There are thousands of columns families
D. The column names are randomly generated
Why would a company decide to use HBase to replace an existing relational database?
A. It is required for performing ad-hoc queries.
B. Varying formats of input data requires columns to be added in real time.
C. The company's employees are already fluent in SQL.
D. Existing SQL code will run unchanged on HBase.
Which metric would be most helpful in identifying a node that may cause network disruption if the node were removed?
A. Degree
B. Closeness
C. Betweenness
D. PageRank
What is NOT a category of a NoSQL data store?
A. Columnar
B. Document
C. Key/Value
D. Flat File
You are analyzing written transcripts of focus groups conducted on product X. You approach is to use TFIDF for your analysis.
What combination of TF-IDF scores should you examine to ensure you only report on the most important terms?
A. High TF score and high DF score
B. High TF score and high IDF score
C. High TF score and low IDF score
D. Low TF score and low DF score
What best describes tokenization?
A. Adding lexical relations to the raw text
B. Converting text into the list of terms
C. Converting text into a list of unique terms
D. Reducing variant forms of tokens to their base forms
How can you improve processing performance in HIVE?
A. Partition tables
B. Run the SET hive.exec.parallel = false command
C. Ensure highly normalized tables and use joins
D. Minimize bucketing
If two of the communities are re-designated to be one community, how does that change the network characteristics?
Refer to the exhibit.
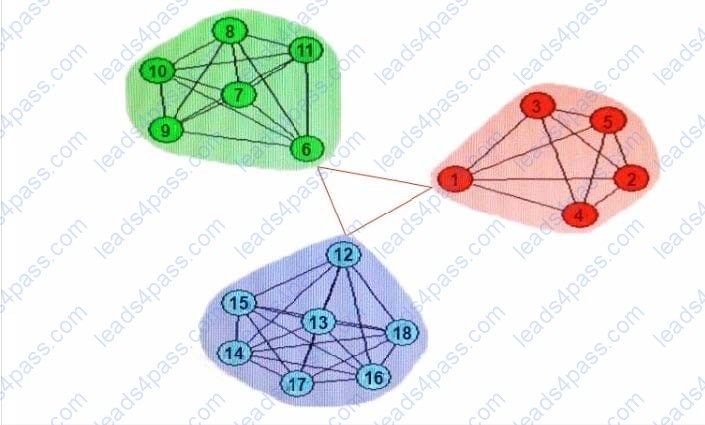
A. Neighborhood overlap would increase
B. Network diameter would decrease
C. Modularity would increase
D. Modularity would decrease
What do first-order and second-order Markov processes have in common concerning next word prediction?
A. Both use WordNet to model the probability of the next word
B. Both are unsupervised methods
C. Both provide the foundation to build a trigram language model
D. Neither makes assumptions about the probability of the next word
![]()
![]()
![]()
![]()
![]()
![]()
All rights are reserved by
leads4pass.com. Any changes, copy or trademarks abuse will be
regarded as infringement.
leads4pass.com will reserve the right to pursue accountability.
Copyright © 2004-
2026 leads4pass.com.