DP-203 Online Practice Questions and Answers
HOTSPOT
You have an Azure Synapse Analytics dedicated SQL pool that contains the users shown in the following table.
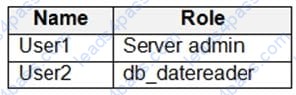
User1 executes a query on the database, and the query returns the results shown in the following exhibit.
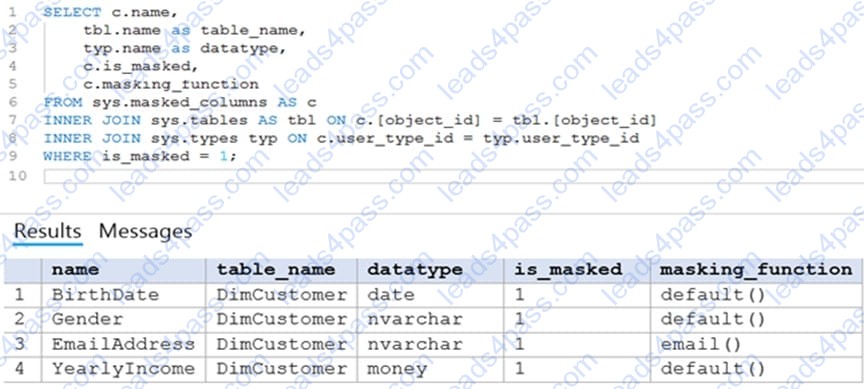
User1 is the only user who has access to the unmasked data.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Hot Area:


HOTSPOT
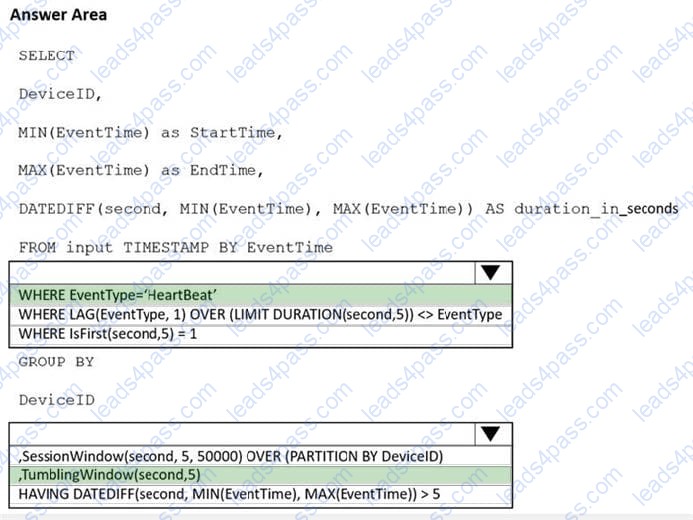
You are implementing an Azure Stream Analytics solution to process event data from devices.
The devices output events when there is a fault and emit a repeat of the event every five seconds until the fault is resolved. The devices output a heartbeat event every five seconds after a previous event if there are no faults present.
A sample of the events is shown in the following table.
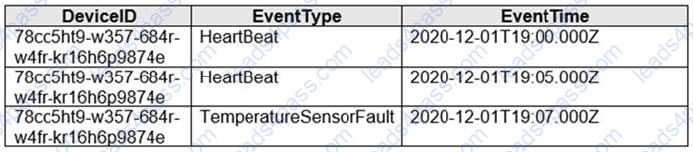
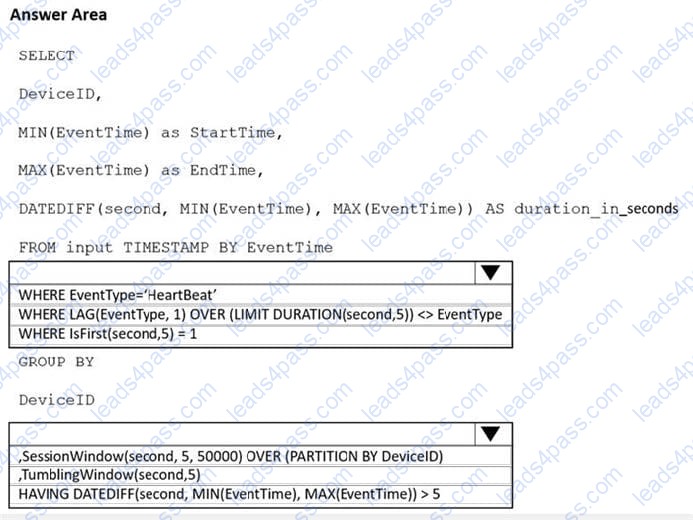
You need to calculate the uptime between the faults.
How should you complete the Stream Analytics SQL query? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
HOTSPOT
You have an Azure subscription that contains an Azure Databricks workspace named databricks1 and an Azure Synapse Analytics workspace named synapse1. The synapse1 workspace contains an Apache Spark pool named pool1.
You need to share an Apache Hive catalog of pool1 with databricks1.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:


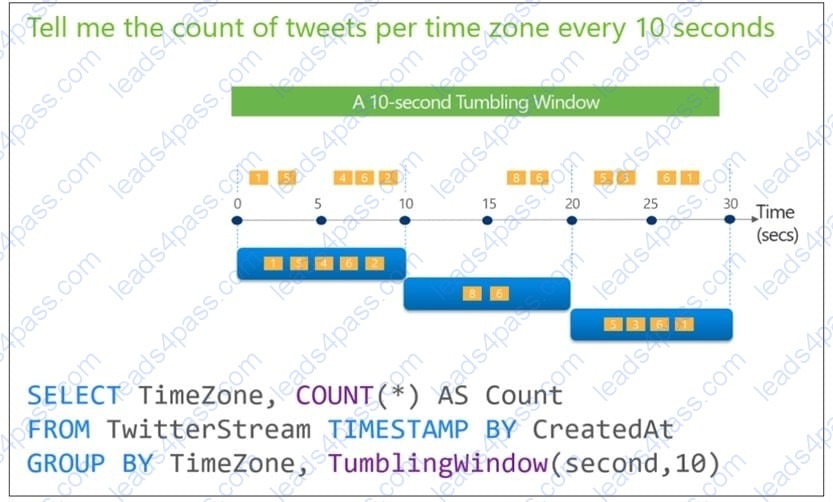
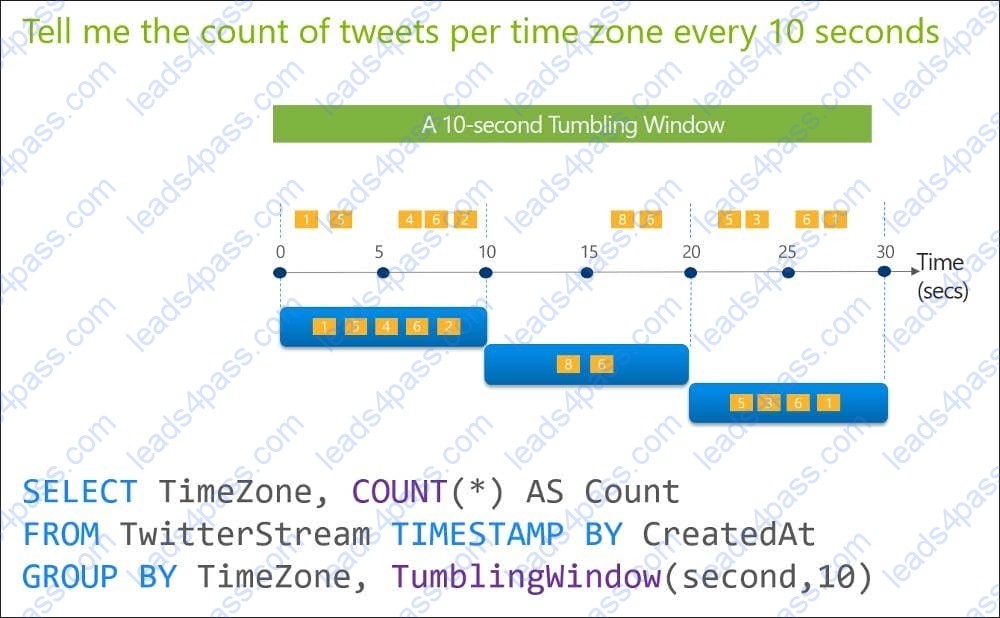
You are designing an Azure Stream Analytics solution that will analyze Twitter data.
You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only once.
Solution: You use a tumbling window, and you set the window size to 10 seconds.
Does this meet the goal?
A. Yes
B. No
You need to implement a Type 3 slowly changing dimension (SCD) for product category data in an Azure Synapse Analytics dedicated SQL pool. You have a table that was created by using the following Transact-SQL statement.
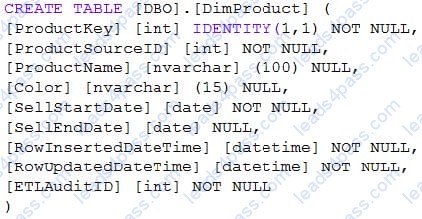
Which two columns should you add to the table? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. [EffectiveStartDate] [datetime] NOT NULL,
B. [CurrentProductCategory] [nvarchar] (100) NOT NULL,
C. [EffectiveEndDate] [datetime] NULL,
D. [ProductCategory] [nvarchar] (100) NOT NULL,
E. [OriginalProductCategory] [nvarchar] (100) NOT NULL,
You are implementing a batch dataset in the Parquet format.
Data files will be produced be using Azure Data Factory and stored in Azure Data Lake Storage Gen2. The files will be consumed by an Azure Synapse Analytics serverless SQL pool.
You need to minimize storage costs for the solution.
What should you do?
A. Use Snappy compression for files.
B. Use OPENROWSET to query the Parquet files.
C. Create an external table that contains a subset of columns from the Parquet files.
D. Store all data as string in the Parquet files.
You are designing a data mart for the human resources (HR) department at your company. The data mart will contain employee information and employee transactions.
From a source system, you have a flat extract that has the following fields:
1.
EmployeeID
2.
FirstName
3.
LastName
4.
Recipient
5.
GrossAmount
6.
TransactionID
7.
GovernmentID
8.
NetAmountPaid
9.
TransactionDate
You need to design a star schema data model in an Azure Synapse Analytics dedicated SQL pool for the data mart.
Which two tables should you create? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. a dimension table for Transaction
B. a dimension table for EmployeeTransaction
C. a dimension table for Employee
D. a fact table for Employee
E. a fact table for Transaction
You use Azure Stream Analytics to receive Twitter data from Azure Event Hubs and to output the data to an Azure Blob storage account.
You need to output the count of tweets from the last five minutes every minute.
Which windowing function should you use?
A. Sliding
B. Session
C. Tumbling
D. Hopping
You are designing an anomaly detection solution for streaming data from an Azure IoT hub. The solution must meet the following requirements:
1.
Send the output to Azure Synapse.
2.
Identify spikes and dips in time series data.
3.
Minimize development and configuration effort. Which should you include in the solution?
A. Azure Databricks
B. Azure Stream Analytics
C. Azure SQL Database
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1. Table1 contains the following:
1.
One billion rows
2.
A clustered columnstore index
3.
A hash-distributed column named Product Key
4.
A column named Sales Date that is of the date data type and cannot be null
Thirty million rows will be added to Table1 each month.
You need to partition Table1 based on the Sales Date column. The solution must optimize query performance and data loading. How often should you create a partition?
A. once per month
B. once per year
C. once per day
D. once per week
![]()
![]()
![]()
![]()
![]()
![]()
All rights are reserved by
leads4pass.com. Any changes, copy or trademarks abuse will be
regarded as infringement.
leads4pass.com will reserve the right to pursue accountability.
Copyright © 2004-
2026 leads4pass.com.