DP-100 Online Practice Questions and Answers
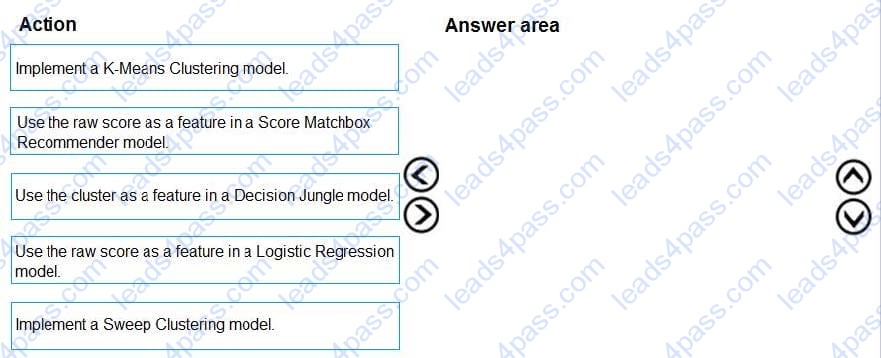
You need to define a modeling strategy for ad response.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:

Your team is building a data engineering and data science development environment. The environment must support the following requirements:
1.
support Python and Scala
2.
compose data storage, movement, and processing services into automated data pipelines
3.
the same tool should be used for the orchestration of both data engineering and data science
4.
support workload isolation and interactive workloads
5.
enable scaling across a cluster of machines
You need to create the environment.
What should you do?
A. Build the environment in Apache Hive for HDInsight and use Azure Data Factory for orchestration.
B. Build the environment in Azure Databricks and use Azure Data Factory for orchestration.
C. Build the environment in Apache Spark for HDInsight and use Azure Container Instances for orchestration.
D. Build the environment in Azure Databricks and use Azure Container Instances for orchestration.
You write a Python script that processes data in a comma-separated values (CSV) file.
You plan to run this script as an Azure Machine Learning experiment.
The script loads the data and determines the number of rows it contains using the following code:

You need to record the row count as a metric named row_count that can be returned using the get_metrics method of the Run object after the experiment run completes.
Which code should you use?
A. run.upload_file(`row_count', `./data.csv')
B. run.log(`row_count', rows)
C. run.tag(`row_count', rows)
D. run.log_table(`row_count', rows)
E. run.log_row(`row_count', rows)
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are creating a model to predict the price of a student's artwork depending on the following variables:
the student's length of education, degree type, and art form.
You start by creating a linear regression model.
You need to evaluate the linear regression model.
Solution: Use the following metrics: Relative Squared Error, Coefficient of Determination, Accuracy, Precision, Recall, F1 score, and AUC.
Does the solution meet the goal?
A. Yes
B. No
You plan to run a Python script as an Azure Machine Learning experiment.
The script must read files from a hierarchy of folders. The files will be passed to the script as a dataset argument.
You must specify an appropriate mode for the dataset argument.
Which mode can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. to_pandas_dataframe ()
B. as_download()
C. as_upload()
D. as mount ()
You are in the process of creating a machine learning model. Your dataset includes rows with null and missing values.
You plan to make use of the Clean Missing Data module in Azure Machine Learning Studio to detect and fix the null and missing values in the dataset.
Recommendation: You make use of the Custom substitution value option.
Will the requirements be satisfied?
A. Yes
B. No
You have been tasked with constructing a machine learning model that translates language text into a different language text.
The machine learning model must be constructed and trained to learn the sequence of the.
Recommendation: You make use of Generative Adversarial Networks (GANs).
Will the requirements be satisfied?
A. Yes
B. No
You have a Jupyter Notebook that contains Python code that is used to train a model.
You must create a Python script for the production deployment. The solution must minimize code maintenance.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Refactor the Jupyter Notebook code into functions
B. Save each function to a separate Python file
C. Define a main() function in the Python script
D. Remove all comments and functions from the Python script
You use the Azure Machine learning SDK foe Python to create a pipeline that includes the following step:
The output of the step run must be cached and reused on subsequent runs when the source.directory value has not changed.
You need to define the step.
What should you include in the step definition?
A. allow.reuse
B. hash_path
C. data-as_input(name-..)
D. version
You need to select a feature extraction method. Which method should you use?
A. Mutual information
B. Mood's median test
C. Kendall correlation
D. Permutation Feature Importance
![]()
![]()
![]()
![]()
![]()
![]()
All rights are reserved by
leads4pass.com. Any changes, copy or trademarks abuse will be
regarded as infringement.
leads4pass.com will reserve the right to pursue accountability.
Copyright © 2004-
2026 leads4pass.com.